
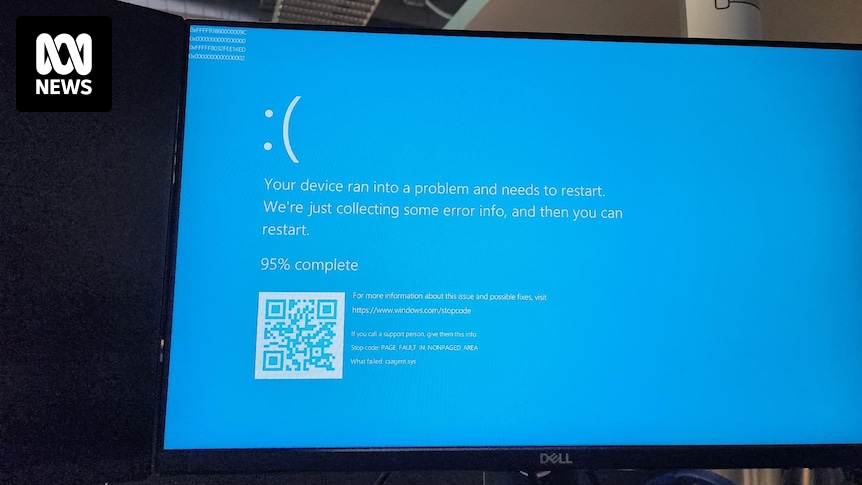
All our servers and company laptops went down at pretty much the same time. Laptops have been bootlooping to blue screen of death. It’s all very exciting, personally, as someone not responsible for fixing it.
Apparently caused by a bad CrowdStrike update.
Edit: now being told we (who almost all generally work from home) need to come into the office Monday as they can only apply the fix in-person. We’ll see if that changes over the weekend…
Reading into the updates some more… I’m starting to think this might just destroy CloudStrike as a company altogether. Between the mountain of lawsuits almost certainly incoming and the total destruction of any public trust in the company, I don’t see how they survive this. Just absolutely catastrophic on all fronts.
Agreed, this will probably kill them over the next few years unless they can really magic up something.
They probably don’t get sued - their contracts will have indemnity clauses against exactly this kind of thing, so unless they seriously misrepresented what their product does, this probably isn’t a contract breach.
If you are running crowdstrike, it’s probably because you have some regulatory obligations and an auditor to appease - you aren’t going to be able to just turn it off overnight, but I’m sure there are going to be some pretty awkward meetings when it comes to contract renewals in the next year, and I can’t imagine them seeing much growth
Don’t most indemnity clauses have exceptions for gross negligence? Pushing out an update this destructive without it getting caught by any quality control checks sure seems grossly negligent.
deleted by creator
explain to the project manager with crayons why you shouldn’t do this
Can’t; the project manager ate all the crayons
Why is it bad to do on a Friday? Based on your last paragraph, I would have thought Friday is probably the best week day to do it.
Most companies, mine included, try to roll out updates during the middle or start of a week. That way if there are issues the full team is available to address them.
deleted by creator
And hence the term read-only Friday.
Was it not possible for MS to design their safe mode to still “work” when Bitlocker was enabled? Seems strange.
I’m not sure what you’d expect to be able to do in a safe mode with no disk access.
rolling out an update to production that there was clearly no testing
Or someone selected “env2” instead of “env1” (#cattleNotPets names) and tested in prod by mistake.
Look, it’s a gaffe and someone’s fired. But it doesn’t mean fuck ups are endemic.
I think you’re on the nose, here. I laughed at the headline, but the more I read the more I see how fucked they are. Airlines. Industrial plants. Fucking governments. This one is big in a way that will likely get used as a case study.
The London Stock Exchange went down. They’re fukd.
Testing in production will do that
Not everyone is fortunate enough to have a seperate testing environment, you know? Manglement has to cut cost somewhere.
What lawsuits do you think are going to happen?
Forget lawsuits, they’re going to be in front of congress for this one
For what? At best it would be a hearing on the challenges of national security with industry.
Don’t we blame MS at least as much? How does MS let an update like this push through their Windows Update system? How does an application update make the whole OS unable to boot? Blue screens on Windows have been around for decades, why don’t we have a better recovery system?
Crowdstrike runs at ring 0, effectively as part of the kernel. Like a device driver. There are no safeguards at that level. Extreme testing and diligence is required, because these are the consequences for getting it wrong. This is entirely on crowdstrike.
This didn’t go through Windows Update. It went through the ctowdstrike software directly.
The amount of servers running Windows out there is depressing to me
The four multinational corporations I worked at were almost entirely Windows servers with the exception of vendor specific stuff running Linux. Companies REALLY want that support clause in their infrastructure agreement.
I’ve worked as an IT architect at various companies in my career and you can definitely get support contracts for engineering support of RHEL, Ubuntu, SUSE, etc. That isn’t the issue. The issue is that there are a lot of system administrators with “15 years experience in Linux” that have no real experience in Linux. They have experience googling for guides and tutorials while having cobbled together documents of doing various things without understanding what they are really doing.
I can’t tell you how many times I’ve seen an enterprise patch their Linux solutions (if they patched them at all with some ridiculous rubberstamped PO&AM) manually without deploying a repo and updating the repo treating it as you would a WSUS. Hell, I’m pleasantly surprised if I see them joined to a Windows domain (a few times) or an LDAP (once but they didn’t have a trust with the Domain Forest or use sudoer rules…sigh).
The issue is that there are a lot of system administrators with “15 years experience in Linux” that have no real experience in Linux.
Reminds me of this guy I helped a few years ago. His name was Bob, and he was a sysadmin at a predominantly Windows company. The software I was supporting, however, only ran on Linux. So since Bob had been a UNIX admin back in the 80s they picked him to install the software.
But it had been 30 years since he ever touched a CLI. Every time I got on a call with him, I’d have to give him every keystroke one by one, all while listening to him complain about how much he hated it. After three or four calls I just gave up and used the screenshare to do everything myself.
AFAIK he’s still the only Linux “sysadmin” there.
“googling answers”, I feel personally violated.
/s
To be fare, there is not reason to memorize things that you need once or twice. Google is tool, and good for Linux issues. Why debug some issue for few hours, if you can Google resolution in minutes.
I’m not against using Google, stack exhange, man pages, apropos, tldr, etc. but if you’re trying to advertise competence with a skillset but you can’t do the basics and frankly it is still essentially a mystery to you then youre just being dishonest. Sure use all tools available to you though because that’s a good thing to do.
Just because someone breathed air in the same space occasionally over the years where a tool exists does not mean that they can honestly say that those are years of experience with it on a resume or whatever.
Just because someone breathed air in the same space occasionally over the years where a tool exists does not mean that they can honestly say that those are years of experience with it on a resume or whatever.
Capitalism makes them to.
Companies REALLY want that support clause in their infrastructure agreement.
RedHat, Ubuntu, SUSE - they all exist on support contracts.
I dunno, but doesn’t like a quarter of the internet kinda run on Azure?
I guess Spotify was running on the other 40%, as many other services
doesn’t like a quarter of the internet kinda run on Azure?
Said another way, 3/4 of the internet isn’t on Unsure cloud blah-blah.
And azure is - shhh - at least partially backed by Linux hosts. Didn’t they buy an AWS clone and forcibly inject it with money like Bobby Brown on a date in the hopes of building AWS better than AWS like they did with nokia? MS could be more protectively diverse than many of its best customers.
I know i was really surprised how many there are. But honestly think of how many companies are using active directory and azure
>Make a kernel-level antivirus
>Make it proprietary
>Don’t test updates… for some reason??I mean I know it’s easy to be critical but this was my exact thought, how the hell didn’t they catch this in testing?
I have had numerous managers tell me there was no time for QA in my storied career. Or documentation. Or backups. Or redundancy. And so on.
Push that into the technical debt. Then afterwards never pay off the technical debt
Completely justified reaction. A lot of the time tech companies and IT staff get shit for stuff that, in practice, can be really hard to detect before it happens. There are all kinds of issues that can arise in production that you just can’t test for.
But this… This has no justification. A issue this immediate, this widespread, would have instantly been caught with even the most basic of testing. The fact that it wasn’t raises massive questions about the safety and security of Crowdstrike’s internal processes.
most basic of testing
“I ran the update and now shit’s proper fucked”
I think when you are this big you need to roll out any updates slowly. Checking along the way they all is good.
The failure here is much more fundamental than that. This isn’t a “no way we could have found this before we went to prod” issue, this is a “five minutes in the lab would have picked it up” issue. We’re not talking about some kind of “Doesn’t print on Tuesdays” kind of problem that’s hard to reproduce or depends on conditions that are hard to replicate in internal testing, which is normally how this sort of thing escapes containment. In this case the entire repro is “Step 1: Push update to any Windows machine. Step 2: THERE IS NO STEP 2”
There’s absolutely no reason this should ever have affected even one single computer outside of Crowdstrike’s test environment, with or without a staged rollout.
God damn this is worse than I thought… This raises further questions… Was there a NO testing at all??
Tested on Windows 10S
My guess is they did testing but the build they tested was not the build released to customers. That could have been because of poor deployment and testing practices, or it could have been malicious.
Such software would be a juicy target for bad actors.
Agreed, this is the most likely sequence of events. I doubt it was malicious, but definitely could have occurred by accident if proper procedures weren’t being followed.
Yes. And Microsoft’s
How exactly is Microsoft responsible for this? It’s a kernel level driver that intercepts system calls, and the software updated itself.
This software was crashing Linux distros last month too, but that didn’t make headlines because it effected less machines.
My apologies I thought this went out with a MS update
You left out > Profit
Oh… Wait…Hang on a sec.
Lots of security systems are kernel level (at least partially) this includes SELinux and AppArmor by the way. It’s a necessity for these things to actually be effective.
You missed most important line:
>Make it proprietary
never do updates on a Friday.
deleted by creator
And especially now the work week has slimmed down where no one works on Friday anymore
Excuse me, what now? I didn’t get that memo.
deleted by creator
I changed jobs because the new management was all “if I can’t look at your ass you don’t work here” and I agreed.
I now work remotely 100% and it’s in the union contract with the 21vacation days and 9x9 compressed time and regular raises. The view out my home office window is partially obscured by a floofy cat and we both like it that way.
I’d work here until I die.
Actually I was not even joking. I also work in IT and have exactly the same opinion. Friday is for easy stuff!
You posted this 14 hours ago, which would have made it 4:30 am in Austin, Texas where Cloudstrike is based. You may have felt the effect on Friday, but it’s extremely likely that the person who made the change did it late on a Thursday.
Never update unless something is broken.
That’s advice so smart you’re guaranteed to have massive security holes.
This is AV, and even possible that it is part of definitions (for example some windows file deleted as false positive). You update those daily.
Yeah my plans of going to sleep last night were thoroughly dashed as every single windows server across every datacenter I manage between two countries all cried out at the same time lmao

How many coffee cups have you drank in the last 12 hours?
I work in a data center
I lost count
What was Dracula doing in your data centre?
Because he’s Dracula. He’s twelve million years old.
THE WORMS
I work in a datacenter, but no Windows. I slept so well.
Though a couple years back some ransomware that also impacted Linux ran through, but I got to sleep well because it only bit people with easily guessed root passwords. It bit a lot of other departments at the company though.
This time even the Windows folks were spared, because CrowdStrike wasn’t the solution they infested themselves with (they use other providers, who I fully expect to screw up the same way one day).
There was a point where words lost all meaning and I think my heart was one continuous beat for a good hour.
Did you feel a great disturbance in the force?
Oh yeah I felt a great disturbance (900 alarms) in the force (Opsgenie)
How’s it going, Obi-Wan?
Here’s the fix: (or rather workaround, released by CrowdStrike) 1)Boot to safe mode/recovery 2)Go to C:\Windows\System32\drivers\CrowdStrike 3)Delete the file matching “C-00000291*.sys” 4)Boot the system normally
It’s disappointing that the fix is so easy to perform and yet it’ll almost certainly keep a lot of infrastructure down for hours because a majority of people seem too scared to try to fix anything on their own machine (or aren’t trusted to so they can’t even if they know how)
Might seem easy to someone with a technical background. But the last thing businesses want to be doing is telling average end users to boot into safe mode and start deleting system files.
If that started happening en masse we would quickly end up with far more problems than we started with. Plenty of users would end up deleting system32 entirely or something else equally damaging.
I do IT for some stores. My team lead briefly suggested having store managers try to do this fix. I HARD vetoed that. That’s only going to do more damage.
I wouldn’t fix it if it’s not my responsibly at work. What if I mess up and break things further?
When things go wrong, best to just let people do the emergency process.
deleted by creator
I’m on a bridge still while we wait for Bitlocker recovery keys, so we can actually boot into safemode, but the Bitkocker key server is down as well…
Man, it sure would suck if you could still get to safe mode from pressing f8. Can you imagine how terrible that’d be?
You hold down Shift while restarting or booting and you get a recovery menu. I don’t know why they changed this behaviour.
That was the dumbest thing to learn this morning.
A driver failure, yeesh. It always sucks to deal with it.
Not that easy when it’s a fleet of servers in multiple remote data centers. Lots of IT folks will be spending their weekend sitting in data center cages.
CrowdStrike: It’s Friday, let’s throw it over the wall to production. See you all on Monday!

^^so ^^hard ^^picking ^^which ^^meme ^^to ^^use
Good choice, tho. Is the image AI?
It’s a real photograph from this morning.
Not sure, I didn’t make it. Just part of my collection.
Fair enough!
When your push to prod on Friday causes a small but measurable drop in global GDP.
Actually, it may have helped slow climate change a little
The earth is healing 🙏
For part of today
With all the aircraft on the ground, it was probably a noticeable change. Unfortunately, those people are still going to end up flying at some point, so the reduction in CO2 output on Friday will just be made up for over the next few days.
Definitely not small, our website is down so we can’t do any business and we’re a huge company. Multiply that by all the companies that are down, lost time on projects, time to get caught up once it’s fixed, it’ll be a huge number in the end.
GDP is typically stated by the year. One or two days lost, even if it was 100% of the GDP for those days, would still be less than 1% of GDP for the year.
I know people who work at major corporations who said they were down for a bit, it’s pretty huge.
Does your web server run windows? Or is it dependent on some systems that run Windows? I would hope nobody’s actually running a web server on Windows these days.
I have a absolutely no idea. Not my area of expertise.
They did it on Thursday. All of SFO was BSODed for me when I got off a plane at SFO Thursday night.

Was it actually pushed on Friday, or was it a Thursday night (US central / pacific time) push? The fact that this comment is from 9 hours ago suggests that the problem existed by the time work started on Friday, so I wouldn’t count it as a Friday push. (Still, too many pushes happen at a time that’s still technically Thursday on the US west coast, but is already mid-day Friday in Asia).
I’m in Australia so def Friday. Fu crowdstrike.
Seems like you should be more mad at the International Date Line.
This is going to be a Big Deal for a whole lot of people. I don’t know all the companies and industries that use Crowdstrike but I might guess it will result in airline delays, banking outages, and hospital computer systems failing. Hopefully nobody gets hurt because of it.
Big chunk of New Zealands banks apparently run it, cos 3 of the big ones can’t do credit card transactions right now
It was mayhem at PakNSave a bit ago.
cos 3 of the big ones can’t do credit card transactions right now
Bitcoin still up and running perhaps people can use that
Bitcoin Cash maybe. Didn’t they bork Bitcoin (Core) so you have to wait for confirmations in the next block?
Several 911 systems were affected or completely down too

Ironic. They did what they are there to protect against. Fucking up everyone’s shit
CrowdStrike has a new meaning… literally Crowd Strike.
They virtually blew up airports
An offline server is a secure server!
There is nothing unsafer than local networks.
AV/XDR is not optional even in offline networks. If you don’t have visibility on your network, you are totally screwed.
Clownstrike
Crowdshite haha gotem
CrowdCollapse
The thought of a local computer being unable to boot because some remote server somewhere is unavailable makes me laugh and sad at the same time.
I don’t think that’s what’s happening here. As far as I know it’s an issue with a driver installed on the computers, not with anything trying to reach out to an external server. If that were the case you’d expect it to fail to boot any time you don’t have an Internet connection.
Windows is bad but it’s not that bad yet.
expect it to fail to boot any time you don’t have an Internet connection.
So, like the UbiSoft umbilical but for OSes.
Edit: name of publisher not developer.
Yep, stuck at the airport currently. All flights grounded. All major grocery store chains and banks also impacted. Bad day to be a crowdstrike employee!
A few years ago when my org got the ask to deploy the CS agent in linux production servers and I also saw it getting deployed in thousands of windows and mac desktops all across, the first thought that came to mind was “massive single point of failure and security threat”, as we were putting all the trust in a single relatively small company that will (has?) become the favorite target of all the bad actors across the planet. How long before it gets into trouble, either because if it’s own doing or due to others?
I guess that we now know
No bad actors did this, and security goes in fads. Crowdstrike is king right now, just as McAfee/Trellix was in the past. If you want to run around without edr/xdr software be my guest.
Hmm. Is it safer to have a potentially exploitable agent running as root and listening on a port, than to not have EDR running on a well-secured low-churn enterprise OS - sit down, Ubuntu - adhering to best practice for least access and least-services and good role-sep?
It’s a pickle. I’m gonna go with “maybe don’t lock down your enterprise Linux hard and then open a yawning garage door of a hole right into it” but YMMV.
Reality is, if your users are educated, then your more secure than any edr with dumbass users. But we all know this is a pipe dream.
All of the security vendors do it over enough time. McAfee used to be the king of them.
https://www.zdnet.com/article/defective-mcafee-update-causes-worldwide-meltdown-of-xp-pcs/



























