
Ah makes sense. Will try to give this a go tomorrow when i have time/energy. Appreciate it, definitely will do!
Ah makes sense. Will try to give this a go tomorrow when i have time/energy. Appreciate it, definitely will do!
Oh I added the disk resources via shell (via nano) to that config for the NFS server CT, following some guide for bind-mounts. I guess that’s the wrong format and treated them like directories instead of ZFS pools?
I’ll follow the formatting you’ve used (ans I think what results “naturally” from the GUI adding of such a ZFS storage dataset.
And yeah I don’t think replication works if it’s not ZFS, so I need to fix that.
Per your other commend - agreed regarding the snapshotting - it’s already saved me on a Home Assistant VM I have running, so I’d love to have that properly working for the actual data in the ZFS pools too.
Is it generally a best practice to only create the “root” ZFS pool and not these datasets within Proxmox (or any hypervisor)?
Thanks so much for your assistance BTW, this has all been reassuring that I’m not in some lost fool land, haha.
So currently I haven’t re-added any of the data-storing ZFS pools to the Datacenter storage section (wanted to understand what I’m doing before trying anything). Right now my storage.cfg reads as follows (without having added anything):
zfspool: virtualizing
pool virtualizing
content images,rootdir
mountpoint /virtualizing
nodes chimaera,executor,lusankya
sparse 0
zfspool: ctdata
pool virtualizing/ctdata
content rootdir
mountpoint /virtualizing/ctdata
sparse 0
zfspool: vmdata
pool virtualizing/vmdata
content images
mountpoint /virtualizing/vmdata
sparse 0
dir: ISOs
path /virtualizing/ISOs
content iso
prune-backups keep-all=1
shared 0
dir: templates
path /virtualizing/templates
content vztmpl
prune-backups keep-all=1
shared 0
dir: backup
path /virtualizing/backup
content backup
prune-backups keep-all=1
shared 0
dir: local
path /var/lib/vz
content snippets
prune-backups keep-all=1
shared 0
Under my ZFS pools (same on each node), I have the following:

The “holocron” pool is a RAIDZ1 combo of 4x8TB HDDs, “virtualizing” is RAID mirrored 2x2TB SSDs, and “spynet” is a single 4TB SSD (NVR storage).
When you say to “add a fresh disk” - you just mean to add a resource to a CT/VM, right? I trip on the terminology at times, haha. And would it be wise to add the root ZFS pool (such as “holocron”) or to add specific datasets under it (such as "Media or “Documents”)?
I’m intending to create a test dataset under “holocron” to test this all out before I put my real data through any risk, of course.
Ah, I see - this is effectively the same as the first image I shared, but via shell instead of GUI, right?
For my NFS server CT, my config file is as follows currently, with bind-mounts:
arch: amd64
cores: 2
hostname: bridge
memory: 512
mp0: /spynet/NVR,mp=/mnt/NVR,replicate=0,shared=1
mp1: /holocron/Documents,mp=/mnt/Documents,replicate=0,shared=1
mp2: /holocron/Media,mp=/mnt/Media,replicate=0,shared=1
mp3: /holocron/Syncthing,mp=/mnt/Syncthing,replicate=0,shared=1
net0: name=eth0,bridge=vmbr0,firewall=1,gw=192.168.0.1,hwaddr=BC:24:11:62:C2:13,ip=192.168.0.82/24,type=veth
onboot: 1
ostype: debian
rootfs: ctdata:subvol-101-disk-0,size=8G
startup: order=2
swap: 512
lxc.apparmor.profile: unconfined
lxc.cgroup2.devices.allow: a
lxc.cap.drop:
For full context, my list of ZFS pools (yes, I’m a Star Wars nerd):
NAME USED AVAIL REFER MOUNTPOINT
holocron 13.1T 7.89T 163K /holocron
holocron/Documents 63.7G 7.89T 52.0G /holocron/Documents
holocron/Media 12.8T 7.89T 12.8T /holocron/Media
holocron/Syncthing 281G 7.89T 153G /holocron/Syncthing
rpool 13.0G 202G 104K /rpool
rpool/ROOT 12.9G 202G 96K /rpool/ROOT
rpool/ROOT/pve-1 12.9G 202G 12.9G /
rpool/data 96K 202G 96K /rpool/data
rpool/var-lib-vz 104K 202G 104K /var/lib/vz
spynet 1.46T 2.05T 96K /spynet
spynet/NVR 1.46T 2.05T 1.46T /spynet/NVR
virtualizing 1.20T 574G 112K /virtualizing
virtualizing/ISOs 620M 574G 620M /virtualizing/ISOs
virtualizing/backup 263G 574G 263G /virtualizing/backup
virtualizing/ctdata 1.71G 574G 104K /virtualizing/ctdata
virtualizing/ctdata/subvol-100-disk-0 1.32G 6.68G 1.32G /virtualizing/ctdata/subvol-100-disk-0
virtualizing/ctdata/subvol-101-disk-0 401M 7.61G 401M /virtualizing/ctdata/subvol-101-disk-0
virtualizing/templates 120M 574G 120M /virtualizing/templates
virtualizing/vmdata 958G 574G 96K /virtualizing/vmdata
virtualizing/vmdata/vm-200-disk-0 3.09M 574G 88K -
virtualizing/vmdata/vm-200-disk-1 462G 964G 72.5G -
virtualizing/vmdata/vm-201-disk-0 3.11M 574G 108K -
virtualizing/vmdata/vm-201-disk-1 407G 964G 17.2G -
virtualizing/vmdata/vm-202-disk-0 3.07M 574G 76K -
virtualizing/vmdata/vm-202-disk-1 49.2G 606G 16.7G -
virtualizing/vmdata/vm-203-disk-0 3.11M 574G 116K -
virtualizing/vmdata/vm-203-disk-1 39.6G 606G 7.11G -
So you’re saying to list the relevant four ZFS datasets in there but, instead of as bind-points, as virtual drives (as seen in the “rootfs” line)? Or rather, as “storage backed mount points” from here:
https://pve.proxmox.com/wiki/Linux_Container#_storage_backed_mount_points
Hopefully I’m on the right track!
Oh I didn’t think the gap window is a bug - I was just acknowledging it, and I’m OK with it.
Definitely some ideas one day for the future but with my current time, architecture, and folks depending on certain services (and my own sanity with the many months I already spent on this), not really looking to re-do anything or wipe drives.
Just want to make the best of my ZFS situation for now - I know it can’t do everything that Ceph and GlusterFS can do.
Hmm, alright - yeah my other nodes have the same ZFS pools already made.
For adding a virtual drive, you mean going to this section, and choosing “Add: Hard Disk” then selecting whatever ZFS pool I would have added under the prior screenshot, under the highlighted red “Storage” box? Will the VM “see” the data already in that pool if it is attached to it like this?
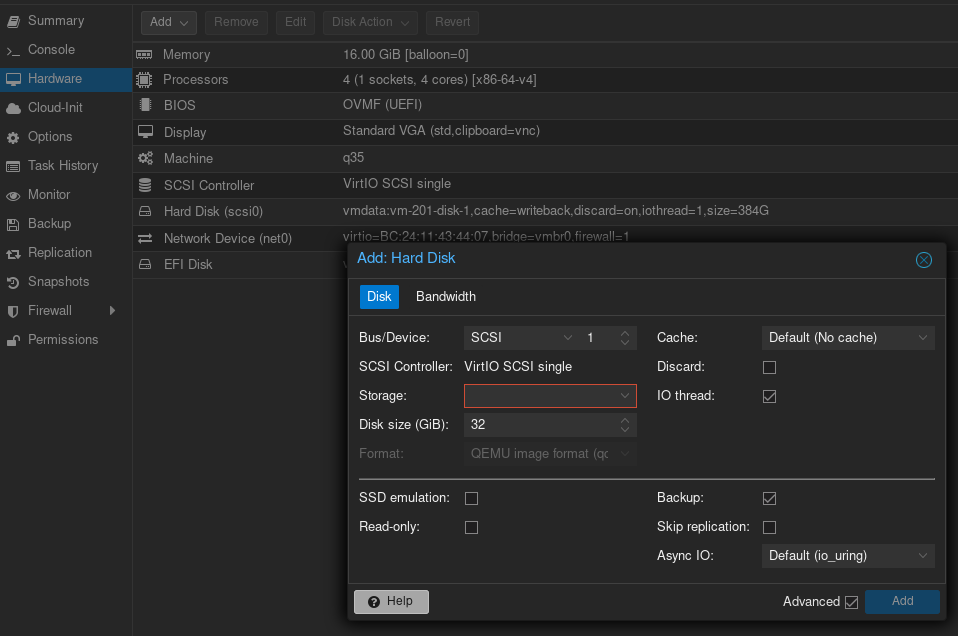
Sorry for my ignorance - I’m a little confused by the “storagename:dataset” thing you mentioned?
And for another dumb question - when you say “copy the data into a regularly made virtual drive on the guest” - how is this different exactly?
One other thing comes to mind - instead of adding the ZFS pools to the VMs, what if I added them to my CT that runs an NFS server, via Mount Point (GUI) instead of the bind-mount way I currently have? Of course, I would need to add my existing ZFS pools to the Datacenter “Storage” section in the same way as previous discussed (with the weird content categories).
Yep that’s also been a concern of mine - I don’t have replication coming from the other nodes as well.
When you say let PVE manage all of the replication - I guess that’s what the main focus of this post is - how? I have those ZFS data pools that are currently just bind-mounted to two CTs, with the VMs mapping to them via NFS (one CT being an NFS server). It’s my understanding that bind-mounted items aren’t supported to be replicated alongside the CTs to which they are attached.
Is there some other, better way to attach them? This is where that italics part comes in - can I just “Add Storage” for these pools and thenadd them via GUI to attach to CTs or VMs, even though they don’t fit those content categories?

Hmm, O.K., so you do that part I mentioned in italics? This section under Datacenter, to add those ZFS pools storing data? And then attach them to a VM via GUI?
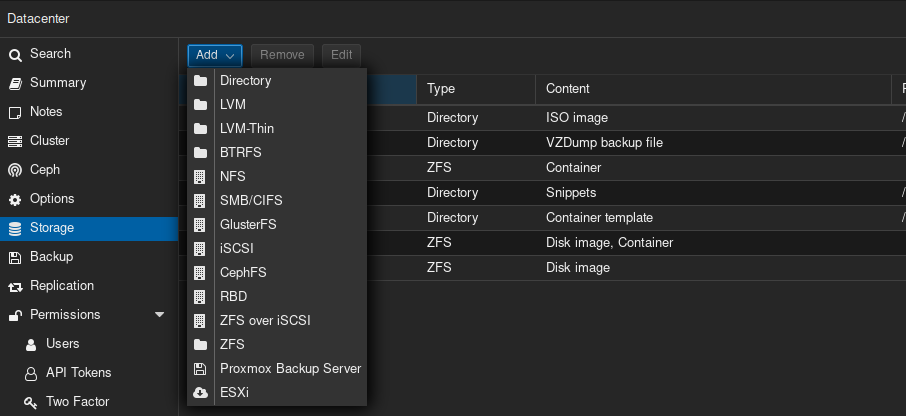
If I’m understanding correctly, what “Content” selection do you choose for your data files in such pools?
Former USAF JAG here (lawyer). I was always a tech geek, undergrad major was in MIS actually, but I didn’t enjoy coding. Always ran Plex on the side, built my own computers, etc. Grew up with my Dad using Linux everywhere (I found this annoying as I just wanted to play games on Windows).
I didn’t enjoy law (surprise!). I was disillusioned with the criminal justice system too. Quit the law in 2020. Then suddenly had quality time by global happenstance to rethink my life path.
I work in IT now. Restarted at the bottom of a new career but I’m in deep nerd territory now - Proxmox servers, Home Assistant, networks with VLANs, OPNsense router, 22U server rack, Linux as my daily driver, etc.
Much happier now.

Yes it only works on Pixel phones. For other devices I recommend looking at DivestOS, CalyxOS, and LineageOS - in that order from best to worst insofar as de-Googling and privacy are concerned.
Hello friend. Indian American here. My parents immigrated here, and their ticket in was education. I understand your grades aren’t great, and I also acknowledge that my parents did come from middle-to-upper-class privilege.
I work for an IT company who employees (not outsources) individuals in India. Several of them have left India to come to the U.S. or Canada. For all of them, education has always been the way out. They knew they wanted out, so they grinded hard in the short-term, and applied aggressively abroad for graduate-level education.
Find a niche in something that does interest you. It seems you are very socioeconomically aware, consider something in such a realm that makes you stand out (yes, I understand this is easier said than done, especially in a nation of 1.3…1.4? billion).
Saying that, also understand that STEM-related expertise areas are much more sought after. So it might not be a bad idea to focus on that side and/or diversify.
I won’t contest a lot of what you said about India - much of that is accurate. Some of that is more cynical than necessary. But change is slow and it would be wrong of me to tell you to stay and change a nation in a region notoriously resistant to change. Unless you’re the next coming of Barack Obama charisma, in which case, please help change India, hahaha.
You’re young, you have plenty of time. So don’t feel burdened not finding a spark at this era in your life. My Mom immigrated here only after marriage, when she was 28. The coworkers I’ve mentioned have all been in their late 20s or early-to-mid 30s.
I want to add - you’re not worthless. Don’t devalue yourself needlessly based on the decrees of an unfair and unjust society or uncaring peers and family.
If you are on iOS, I recommend using the following:
It’s open-source and recommended by PrivacyGuides.
I’m on Android, where that’s also an option I believe, but I’m using Aegis.
Bitwarden also came out with an open-source MFA app, though it’s a bit new so I’d recommend waiting to see what folks say about it.
Raivo uses to be a good (and the only decent) choice for iOS but I believe it was acquired by an insidious company.
As a huge fan of Star Wars content from before Disney got involved and poisoned it (notable exceptions of Rogue One, Andor, some of the animated shows, etc.), I utilize warship names from the Expanded Universe (now called “Legends”) - what I like to call True Star Wars.
My main server is Chimaera. My backup server that also performs as an NVR is Lusankya. My separate mostly-NAS server away from my server rack is Admonitor.
I have sci-fi themed names (not all Star Wars - two other franchises represented here, virtual kudos to those who can identify) for the storage pools too (using TrueNAS SCALE on all three servers):

Conservatism.
Instead of LineageOS, see if DivestOS exists for your device. It’s more secure and private than LineageOS, and forked from it.
For your launcher - try Neo Launcher and its companion, Neo Feed.
QKSMS is best for SMS at the moment.
For contacts and phone, try using whatever comes stock with DivestOS. It’s probably the AOSP base of what Google uses for Google Contacts and their Phone app.
I use Google Camera for my Pixel solely because of the processing you can’t get elsewhere that lets me use my phone’s camera to its full potential.
Otherwise try Secure Camera from GrapheneOS team, and/or Open Camera.
The FossifyOrg forks of the Simple Mobile Tools suite is also worth investigating.
Everything is political. Everything. Only the ignorant ignore this.
You might have missed when they tried to overthrow democracy in the January 6th terrorist attack. These people are not our people. It’s a brewing war. They refused compromise for decades - it has been tried. Your lack of knowledge of history and politics is showing.
You’re too naive.
There is a paradox of tolerating the intolerant.
Our enemy are fascists, plain and simple. They don’t deserve a voice. The only intelligent approsch is to combat them, as their purpose is to subvert democracy, however horribly flawed a system it is, with exclusionary autocracy. This era isn’t one of two parties who both believe in democracy, finding some disagreement on issues. This is a crisis, “post-fact” era where truth is ignored, corruption and power-grabs are blatant and undisguised, and bigotry is rampant.
No.
Society tolerating people with evil views begets more evil.


It took me a while to find a moment to give it a go, but I created a test dataset under my main ZFS pool and added it to a CT - it did snapshots and replication fine.
The one question I have is - for the bind-mounts, I didn’t have any size set - and they accurately show remaining disk space for the pool they are on.
Here it seems I MUST give a size? Is that correct? I didn’t really want to allocate a smaller size for any given dataset, if possible. I saw something about storage-backed mount points, and adding them (via config file, versus GUI) and setting “size=0” - if this is of a ZFS dataset, would this “turn” it into a directory and prevent snapshotting or replicating to other nodes?
One last question - when I’m adding anything to the Datacenter’s storage section, do I want to check availability for all nodes? Does that matter?
Thanks again!